Code
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (8, 8)You will learn how to optimize the predictions generated by your neural networks. One of the most important techniques in deep learning is called backward propagation. In the second half of this course, you will be able to build on your understanding of how it works.
This Optimizing a neural network with backward propagation is part of [Datacamp course: Introduction to Deep Learning in Python] In a wide range of fields such as robotics, natural language processing, image recognition, and artificial intelligence, including AlphaGo, deep learning is the technique behind the most exciting capabilities. As part of this course, you will gain hands-on, practical experience using deep learning with Keras 2.0, the latest version of a cutting-edge Python library for deep learning.
This is my learning experience of data science through DataCamp. These repository contributions are part of my learning journey through my graduate program masters of applied data sciences (MADS) at University Of Michigan, DeepLearning.AI, Coursera & DataCamp. You can find my similar articles & more stories at my medium & LinkedIn profile. I am available at kaggle & github blogs & github repos. Thank you for your motivation, support & valuable feedback.
These include projects, coursework & notebook which I learned through my data science journey. They are created for reproducible & future reference purpose only. All source code, slides or screenshot are intellactual property of respective content authors. If you find these contents beneficial, kindly consider learning subscription from DeepLearning.AI Subscription, Coursera, DataCamp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (8, 8)Now you’ll get to change weights in a real network and see how they affect model accuracy!
Have a look at the following neural network:
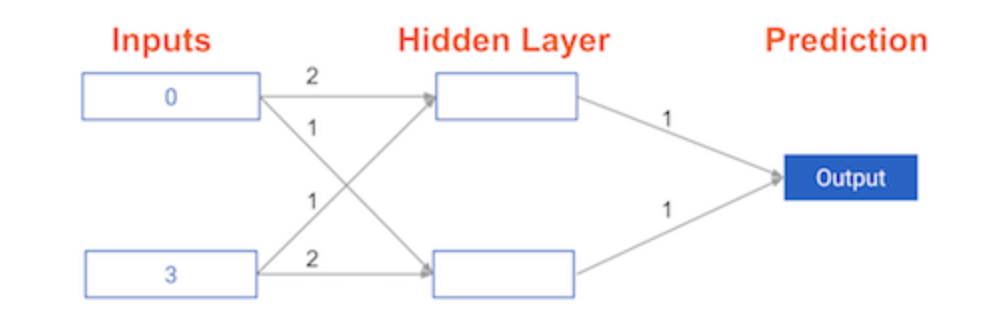
Its weights have been pre-loaded as weights_0. Your task in this exercise is to update a single weight in weights_0 to create weights_1, which gives a perfect prediction (in which the predicted value is equal to target_actual: 3).
def relu(input):
'''Define your relu activatino function here'''
# Calculate the value for the output of the relu function: output
output = max(0, input)
# Return the value just calculate
return outputdef predict_with_network(input_data_point, weights):
node_0_input = (input_data_point * weights['node_0']).sum()
node_0_output = relu(node_0_input)
node_1_input = (input_data_point * weights['node_1']).sum()
node_1_output = relu(node_1_input)
hidden_layer_values = np.array([node_0_output, node_1_output])
input_to_final_layer = (hidden_layer_values * weights['output']).sum()
model_output = relu(input_to_final_layer)
return(model_output)input_data = np.array([0, 3])
# Sample weights
weights_0 = {
'node_0': [2, 1],
'node_1': [1, 2],
'output': [1, 1]
}
# The actual target value, used to calculate the error
target_actual = 3
# Make prediction using original weights
model_output_0 = predict_with_network(input_data, weights_0)
# Calculate error: error_0
error_0 = model_output_0 - target_actual
# Create weights that caus the network to make perfect prediction (3): weights_1
weights_1 = {
'node_0': [2, 1],
'node_1': [1, 2],
'output': [1, 0]
}
# Make prediction using new weights: model_output_1
model_output_1 = predict_with_network(input_data, weights_1)
# Calculate error: error_1
error_1 = model_output_1 - target_actual
# Print error_0 and error_1
print(error_0)
print(error_1)6
0You’ve seen how different weights will have different accuracies on a single prediction. But usually, you’ll want to measure model accuracy on many points. You’ll now write code to compare model accuracies for two different sets of weights, which have been stored as weights_0 and weights_1.
input_data is a list of arrays. Each item in that list contains the data to make a single prediction. target_actuals is a list of numbers. Each item in that list is the actual value we are trying to predict.
weights_0 = {'node_0': np.array([2, 1]), 'node_1': np.array([1, 2]), 'output': np.array([1, 1])}
weights_1 = {'node_0': np.array([2, 1]), 'node_1': np.array([1, 1.5]), 'output': np.array([1, 1.5])}
input_data = [np.array([0, 3]), np.array([1, 2]), np.array([-1, -2]), np.array([4, 0])]
target_actuals = [1, 3, 5, 7]from sklearn.metrics import mean_squared_error
# Create model_output_0
model_output_0 = []
# Create model_output_1
model_output_1 = []
# Loop over input_data
for row in input_data:
# Append prediction to model_output_0
model_output_0.append(predict_with_network(row, weights_0))
# Append prediction to model_output_1
model_output_1.append(predict_with_network(row, weights_1))
# Calculate the mean squared error for model_output_0: mse_0
mse_0 = mean_squared_error(model_output_0, target_actuals)
# Calculate the mean squared error for model_output_1: mse_1
mse_1 = mean_squared_error(model_output_1, target_actuals)
# Print mse_0 and mse_1
print("Mean squared error with weights_0: %f" % mse_0)
print("Mean squared error with weights_1: %f" % mse_1)Mean squared error with weights_0: 37.500000
Mean squared error with weights_1: 49.890625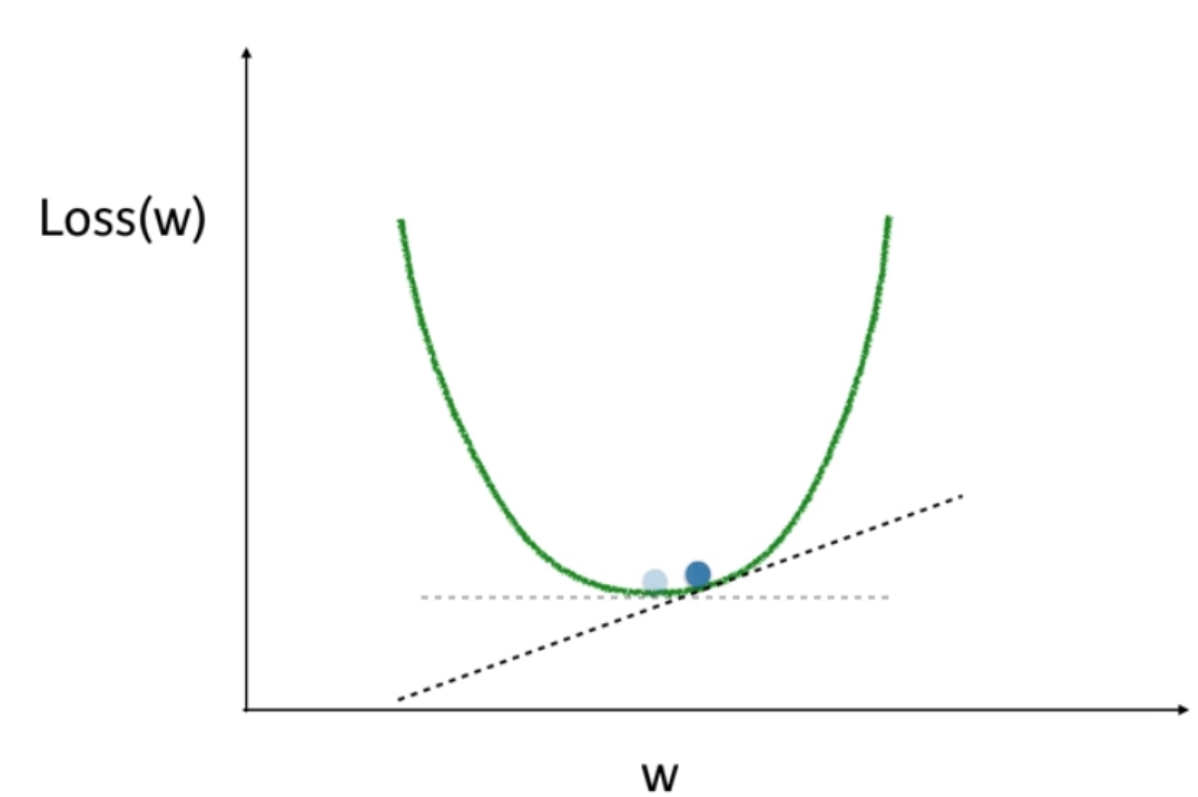

You’re now going to practice calculating slopes. When plotting the mean-squared error loss function against predictions, the slope is 2 * x * (xb-y), or 2 * input_data * error. Note that x and b may have multiple numbers (x is a vector for each data point, and b is a vector). In this case, the output will also be a vector, which is exactly what you want.
You’re ready to write the code to calculate this slope while using a single data point. You’ll use pre-defined weights called weights as well as data for a single point called input_data. The actual value of the target you want to predict is stored in target.
weights = np.array([0, 2, 1])
input_data = np.array([1, 2, 3])
target = 0# Calculate the predictions: preds
preds = (input_data * weights).sum()
# Calculate the error: error
error = preds - target
# Calculate the slope: slope
slope = 2 * input_data * error
# Print the slope
print(slope)[14 28 42]When you add those slopes to your weights, you will move in the right direction. However, it is possible to move too far in that direction. In order to determine if the model is improving, you will want to take a small step first, using a lower learning rate.
# Set the learning rate: learning_rate
learning_rate = 0.01
# Calculate the predictions: preds
preds = (weights * input_data).sum()
# Calculate the error: error
error = preds - target
# Calculate the slope: slope
slope = 2 * input_data * error
# Update the weights: weights_updated
weights_updated = weights - learning_rate * slope
# Get updated predictions: preds_updated
preds_updated = (weights_updated * input_data).sum()
# Calculate updated error: error_updated
error_updated = preds_updated - target
# Print the original error
print(error)
# Print the updated error
print(error_updated)7
5.04As you make multiple updates, you can improve the weights of your model dramatically, and see how the predictions improve as you do so.
You can keep your code clean by using the get_slope() function, which takes input_data, target, and weights as arguments. A similar function, get_mse(), is also available.
In this network, there are no hidden layers, and it goes directly from the input (with three nodes) to the output. Weights consists of a single array.
def get_error(input_data, target, weights):
preds = (weights * input_data).sum()
error = preds - target
return error
def get_slope(input_data, target, weights):
error = get_error(input_data, target, weights)
slope = 2 * input_data * error
return slope
def get_mse(input_data, target, weights):
errors = get_error(input_data, target, weights)
mse = np.mean(errors ** 2)
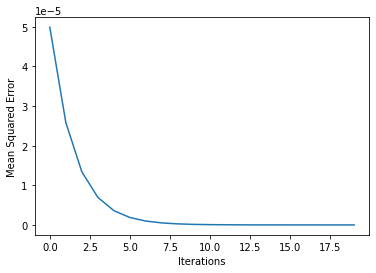
return msen_updates = 20
mse_hist = []
# Iterate over the number of updates
for i in range(n_updates):
# Calculate the slope: slope
slope = get_slope(input_data, target, weights)
# Update the weights: weights
weights = weights - learning_rate * slope
# Calculate mse with new weights: mse
mse = get_mse(input_data, target, weights)
# Append the mse to mse_hist
mse_hist.append(mse)
# Plot the mse history
plt.plot(mse_hist);
plt.xlabel('Iterations');
plt.ylabel('Mean Squared Error');
print("\nAs you can see, the mean squared error decreases as the number of iterations go up. ")
As you can see, the mean squared error decreases as the number of iterations go up.